Introduction
In this multi-part tutorial series, we will be building a Retrieval Augmented Generation pipeline for question-answering. RAG is a good approach to tackle hallucination, enabling LLMs to generate accurate and factually consistent answers.
Retrieval Augmented Generation
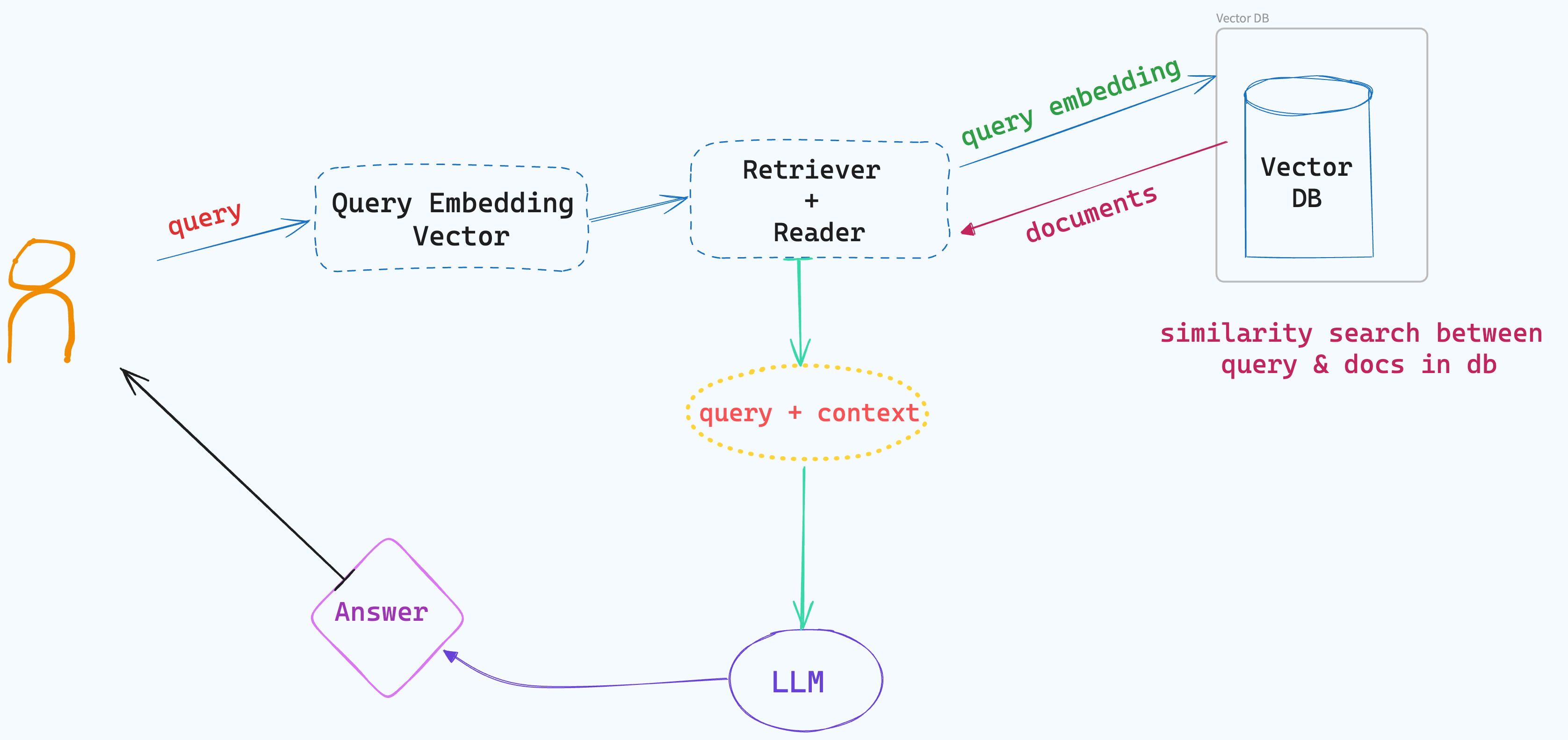
A simple retrieval augmented generation pipeline consists of a vector database that houses the knowledge documents, a component that retrieves information relevant to the query, and an LLM which makes use of the retrieved information (or context) to generate an answer.
When a user asks a question to our system, the system first searches the vector database for documents containining information relevant to the query. This is done by performing a semantic similarity search between the query (converted to an embedding vector) and the documents stored in the vector database which helps us identify the most similar documents. Then, the selected documents are ranked according to their similarity (to the query), and the portion of text containing the answer is extracted from each of the documents.
Once, the information needed to answer the question is extracted, the LLM is prompted to generate an answer based on this context and the user question.
What does RAG solve?
RAG enables LLMs to generate informative, up-to-date, and, factually correct answers. RAG is quickly turning out to be a preferred way to improve the LLM’s performance and mitigate the hallucination problem. In a nutshell, RAG addresses the following problems:
RAG enables you to deploy general LLMs for your specific domain without the need for fine-tuning. Fine-tuning is an expensive, time-consuming process requiring a significant amount of technical expertise.
RAG also makes it much easier to provide up-to-date information to the LLM; by decoupling the answer generation process from your knowledge base, you remove the need to fine-tune the LLM each time your knowledge base is updated, saving on money, time, compute and developer resources.
Perhaps one of RAG’s biggest advantages is that it enables accurate debugging by tracing the knowledge document used to generate answers. This allows you to track down and update a knowledge document if you find that the generated answers are lacking in any aspect.
Another advantage of RAG compared to fine-tuning is the ability to “forget” information. When you fine-tune an LLM on some knowledge, that knowledge becomes a part of the model and getting the model to forget that information is neither straightforward nor easy. With RAG, however, you need only delete or update your database to remove information you no longer want the LLM to access.
What can you build with a RAG pipeline + some use-cases?
Some of the most common applications include developing chatbots for specialised domains like healthcare, finance, legal etc. You can spin up a RAG solution for any situation where you want to make it easy to access information buried within manuals, policy documents, etc.
A RAG solution may provide a conversational interface to information retrieval tasks, and equip people to access specific knowledge quickly. For example, you could collect your company’s proprietary documents, technical manuals, or policy documents, and setup a knowledge base, and build an internal tool for your employees to quickly search for information. Such a chatbot can help improve the efficiency of your HR/people/internal ops teams.
Or you could extend FAQs or FRST (frequently raised service tickets) for common problems, provide as documents a set of instructions and have the chatbot handle these requests freeing up your service team’s queues.
High-level Overview of this RAG project
Our RAG solution will be built as a pipeline with the major components being be the vector database (to store documents), and the question answering pipeline with the LLM.
We will be setting up a vector database to store and index our documents, LLM (QA) pipeline will be hosted as an API endpoint, and a simple web app so we can interact with the system over the web.
We will be using Haystack as the framework to build our QA pipeline and Databricks’ documentation pages as our “specialised knowledge” for our LLM to answer questions regarding Databricks setup + FAQs.
LLM Frameworks like Haystack by Deepset AI and LangChain provide out-of-the-box pipelines and methods for getting started with common NLP tasks. I decided to go with Haystack in this project.
In the next blog post, we will create our dataset and apply preprocessing. Then, we will store our cleaned data in a document store.
Stay tuned (:
Happy Programming!